

Ebook
2023 OWASP API Security Top 10 Best Practices
After four long years since the original guidelines were created, the Open Web Application Security Project (OWASP) has now updated their Top 10…
Read
Platform Features
By Need
By Industry
Partner Program
Our Partners
Key Alliances
Resource Center
{ "term_id": 163, "name": "Tanya Janca", "slug": "tanya-janca", "term_group": 0, "term_taxonomy_id": 163, "taxonomy": "wpx-authors", "description": "", "parent": 0, "count": 2, "filter": "raw" }
The Open Worldwide Application Security Project, better known as OWASP, is about to release the new version of their famous API Security Top 10 list, and we have a copy of the release candidate. What is the release candidate? Well it’s a fancy way of saying the “sneak peek”, which means the list isn’t currently final. OWASP is currently accepting feedback from industry professionals on the proposed list before it’s finalized. However, despite the deliberation going on, there’s a lot of new great stuff on the list to review!
Let’s take a look at the proposed changes in the graph below.
|
2019 |
2023 |
Changes |
| 1 Broken Object Level Authorization | 1 Broken Object Level Authorization | SAME |
| 2 Broken User Authentication | 2 Broken Authentication | SAME |
| 3 Excessive Data Exposure | 3 Broken Object Property Level Authorization |
NEW |
| 4 Lack of Resources & Rate Limiting | 4 Unrestricted Resource Consumption | UPDATED |
| 5 Broken Function Level Authorization | 5 Broken Function Level Authorization | SAME |
| 6 Mass Assignment | 6 Server Side Request Forgery | NEW |
| 7 Security Misconfiguration | 7 Security Misconfiguration | SAME |
| 8 Injection | 8 Lack of Protection From Automated Threats | UPDATED |
| 9 Improper Assets Management | 9 Improper Asset Management | SAME |
| 10 Insufficient Logging & Monitoring | 10 Unsafe Consumption of APIs | NEW |
TL;DR on the Changes
Let’s dig in, shall we?
The most notable addition to the list is Broken Object Property Level Authorization. Authorization issues remain the biggest risk for API security. Implementing authorization, which I’ll refer to as AuthZ, in APIs is becoming more challenging due to the increased complexity of authorization itself. Why? Well quite simply it’s not managed centrally but rather has become a decentralized mechanism. For example on a functional level, AuthZ can be implemented in the code itself, the API configuration, or in the API Gateway. But on the more granular object-level, every developer must take care to implement role-based authorization based on client IDs matched to objects coming from the back-end systems like a database.
The example below dives a bit deeper into where BOPLA fits with the rest of the authorization issues:
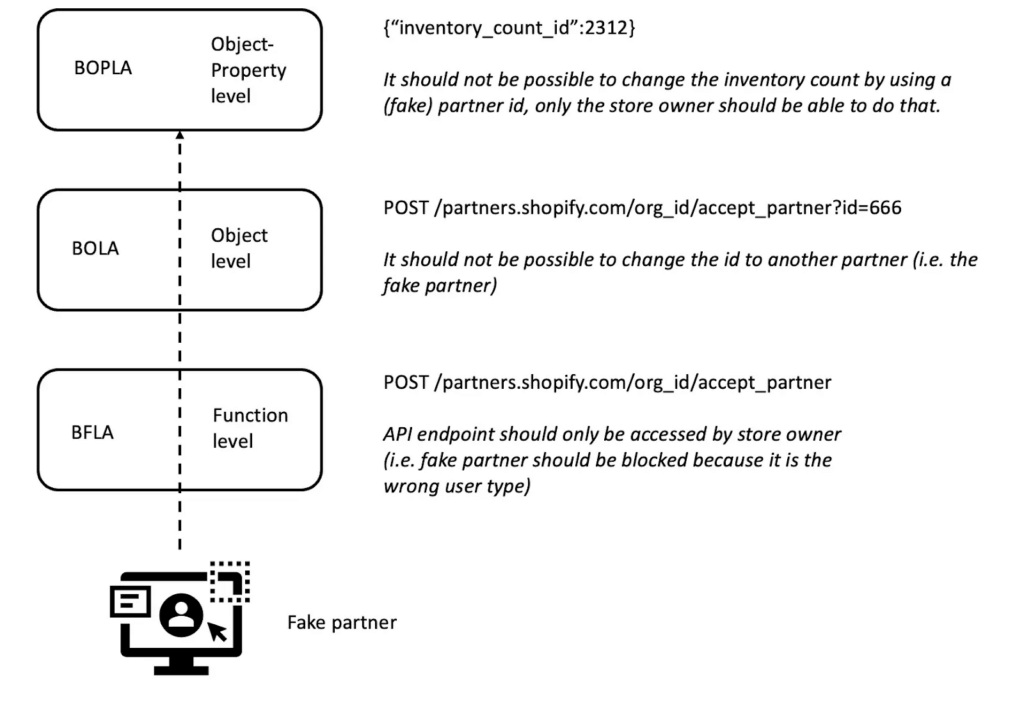
Let’s say we have an ecommerce portal where you can have your business partners sign up to become affiliated with your store. At the function level we need to ensure the API to sign-up new affiliate partners can only be used (as in POST) by the store owner, not the potential affiliate themselves. At the object level we should be able to validate that the store owner (or the fake affiliate) cannot change the partner id and sign-up another party. And finally at the object-property level we should be able to validate that a partner cannot change the inventory of your store.
As noted earlier, this new item on the API Security Top Ten is a combination of Excessive Data Exposure and Mass Assignment. Excessive data exposure refers to showing or otherwise exposing sensitive data to the attacker (which may be in the form of returning too many records, or too many fields within a record, sometimes this means every single record in the entire database). Mass assignment refers to linking fields/properties in the database to user input from the API, such that data from the user is used to automatically update the fields in the database (without validating the information before use). Both of which are highly problematic.
Sometimes the vulnerability is that users see data they shouldn’t see, or that they are able to update data they should not be able to. Both involve data that should not be accessible to the user, and both are caused by having access (reading or changing) object properties (values) they should never have had access to in the first place.
The ideal fix is to not bind object properties to anything we share with, or can be updated by, the user. We should also test for this, verify the user has authorization to access data before we update or share it with them, and avoid any functions that bind to data properties. The OWASP team provides several more strategies, in more detail, in the release candidate document.
APIs provide services. Sometimes the service is to fetch data. Other times the service is to update data, perform a task, send a request to another system, etc. Because APIs don’t have minds of their own like human beings do, they generally don’t question or analyze the requests, they just go off and perform them. If an API receives ‘too many’ requests, or requests that are ‘too big’, unless there is logic within the API to block it, eventually it will crash, run out of resources, or your next cloud bill will be terrifying (thank you autoscaling).
Because APIs can’t tell for themselves what ‘too much’ or ‘too many’ is, we must set limits. This means limits for how much data can be asked for in one request, how many requests in a row from one IP address or system is allowed, and all sorts of other limits! The OWASP team recommends several best practices to add limits, as well as why each of them matters, in the release candidate, and we’ve outlined some for you below in key update #4.
Server-side request forgery happens when a system accepts a URL from an external source (in this case an API), and then makes decisions or saves this URL, without properly validating that input first (before it’s used). The URL then sends a malicious request to somewhere it’s not supposed to go, which can result in all sorts of chaos behind your perimeter’s firewall, such as; enumerating your servers and systems, performing actions against internal systems, and sensitive data exposure.
APIs often fetch data, retrieving data from a database, another API, or a storage container. APIs do this with however much authority their identity (a service account) on the network is given, via whatever access control process is used. When an API is vulnerable to SSRF, it tricks the app into sending requests on the attackers behalf, with all of the same authority that application’s service account is granted on your network. A common SSRF attack is to force the API to gather data from a different place than the API would normally access and bring that sensitive data back to the attacker.
This terrible vulnerability can be avoided in a number of ways! Only accept URLs from a list of approved URLs (an ‘approved list’, sometimes called a ‘whitelist’), test your code thoroughly that performs parsing of URLs, only allow access to any internal services VIA service accounts (blocking your app from asking for resources from the incorrect/unexpected servers) and apply the concept of zero trust when designing your network (blocking all ports/service accounts/etc. unless there is a business requirement to allow such a connection).
APIs need protection from bots, scripts, and any other automated threats even more than regular web applications do. With no GUI front end to protect them, unless you put them behind an API gateway or WAF, you must code your own defenses into your APIs. If we do not protect APIs, automated attacks will always work against our defenceless little web services.
Automated attacks can be denial of service, brute force, credential stuffing…honestly, the sky’s the limit! The risks are very real, common, and harmful. Changing the name of this item is quite helpful, as it makes it more obvious to anyone reading this awareness document that they must add protections against automated threats. This is not an optional defense, it’s mandatory for every API that is publicly exposed to the internet.
Some of the ways to avoid bots include:
When we receive data from anywhere, we should validate that it is what we were expecting. If we are expecting a date, then we should verify it is a date, that it’s in the expected range, and that it is in the format we requested/expect. Anything that is not in alignment with our expectations, we should either reject it entirely (“Improper format, please try again”) or sanitize the input (but only if this is a requirement of the project or business, do not add this of your own volition).
Often programmers will trust the values they receive from APIs, because the API is owned and operated by another business or organization that they trust. They will think “I trust Google/Microsoft/whoever” and thus they assume that means the data from the APIs are also trustworthy. Unfortunately, all humans make mistakes sometimes, and the security of software is almost never guaranteed. It’s very possible that an API from a well-known and well-respected company could have been compromised, been replaced by a malicious API, or sends back data that has a dangerous surprise inside. Validating the data that comes from an API is not a political statement, it’s prudent web security.
If every single programmer, all over the planet, properly validated all inputs, the internet would be a *much* safer place. And the data we receive back from APIs is covered by this statement, it’s considered input to your application. Do not use it to make decisions or save it, until after you have validated that it’s trustworthy.
The OWASP API Security Top Ten list was created to build awareness among security professionals and software developers alike about the common security risks to APIs. This is not the end of your journey, but the beginning. Again, this list just represents the preliminary candidates – we’ll be sure to update you as the list evolves. In the meantime, I definitely recommend getting further acquainted with the current proposed changes. Try out security tools that specialize in APIs, and start securing the APIs where you work! The more you learn, and the more work you do, the better protected your APIs, data, and organization will be!
After four long years since the original guidelines were created, the Open Web Application Security Project (OWASP) has now updated their Top 10…

Now that the OWASP API Security Top 10 has seen its second release, we’ll discuss the changes from the previous version, dive into each category…

Filip Verloy discusses the 2023 OWASP API Security Top 10.
Tanya Janca

Tanya Janca, also known as SheHacksPurple, is the best-selling author of Alice and Bob Learn Application Security. She is also the founder of We Hack Purple, an online learning community that revolves around teaching everyone to create secure software. Tanya has been coding and working in IT for over twenty-five years, is an award-winning public speaker, active blogger and podcaster, and has delivered hundreds of talks on six continents.
All Tanya Janca posts All of Tanya Janca's postsCertified for your security needs.




